There are some choices to be made around how Kafka ingests the data. For details, see, Log in to the ClickHouse client by referring to, Create a Kafka table in ClickHouse by referring to, Create a ClickHouse replicated table, for example, the ReplicatedMergeTree table named.  The Kafka client has been installed.
The Kafka client has been installed.  All connectors are open-sourced. 2022 - EDUCBA.
All connectors are open-sourced. 2022 - EDUCBA. 

 Run the following command to send a message to the topic created in, Use the ClickHouse client to log in to the ClickHouse instance node in.
Run the following command to send a message to the topic created in, Use the ClickHouse client to log in to the ClickHouse instance node in.  Engineers can opt for raw data, analysts for normalized schemas. THE CERTIFICATION NAMES ARE THE TRADEMARKS OF THEIR RESPECTIVE OWNERS. For event streaming, three main functionalities are available: the ability to (1) subscribe to (read) and publish (write) streams of events, (2) store streams of events indefinitely, durably, and reliably, and (3) process streams of events in either real-time or retrospectively. It is in the same VPC as the Kafka cluster and can communicate with each other. A group of Kafka consumers, which can be customized. (On the Dashboard page, click Synchronize on the right side of IAM User Sync to synchronize IAM users.). Step 3: If we want to update the particular version then it can be done by restoring the latest version with a version number, such as, confluent-hub install confluentinc/kafka-connect-jdbc:10.0.0. In fact, if we were to query the view a second time, the row above would not show because it is only intended to be read once. Log in to the node where the Kafka client is installed as the Kafka client installation user. Airbyte integrates with your existing stack. Airbyte is an open-source data integration engine that helps you consolidate your data in your data warehouses, lakes and databases. In a new tmux pane we can start the Kafka console producer to send a test message: If we then go back to our Clickhouse client and query the table: We should see the record has been ingested into Clickhouse directly from Kafka: The Kafka table engine backing this table is not appropriate for long term storage. Thank you very much for your feedback.
Engineers can opt for raw data, analysts for normalized schemas. THE CERTIFICATION NAMES ARE THE TRADEMARKS OF THEIR RESPECTIVE OWNERS. For event streaming, three main functionalities are available: the ability to (1) subscribe to (read) and publish (write) streams of events, (2) store streams of events indefinitely, durably, and reliably, and (3) process streams of events in either real-time or retrospectively. It is in the same VPC as the Kafka cluster and can communicate with each other. A group of Kafka consumers, which can be customized. (On the Dashboard page, click Synchronize on the right side of IAM User Sync to synchronize IAM users.). Step 3: If we want to update the particular version then it can be done by restoring the latest version with a version number, such as, confluent-hub install confluentinc/kafka-connect-jdbc:10.0.0. In fact, if we were to query the view a second time, the row above would not show because it is only intended to be read once. Log in to the node where the Kafka client is installed as the Kafka client installation user. Airbyte integrates with your existing stack. Airbyte is an open-source data integration engine that helps you consolidate your data in your data warehouses, lakes and databases. In a new tmux pane we can start the Kafka console producer to send a test message: If we then go back to our Clickhouse client and query the table: We should see the record has been ingested into Clickhouse directly from Kafka: The Kafka table engine backing this table is not appropriate for long term storage. Thank you very much for your feedback.  Scroll down to upvote and prioritize it, or check our, connectors yet. Kafka offers these capabilities in a secure, highly scalable, and elastic manner. You have selected a star rating. For this reason, Clickhouse has developed a strong offering for integration with Kafka. The total number of consumers cannot exceed the number of partitions in a topic because only one consumer can be allocated to each partition. The most common thing data engineers need to do is to subscribe to data which is being published onto Kafka topics, and consume it directly into a Clickhouse table. Use our webhook to get notifications the way you want.
Scroll down to upvote and prioritize it, or check our, connectors yet. Kafka offers these capabilities in a secure, highly scalable, and elastic manner. You have selected a star rating. For this reason, Clickhouse has developed a strong offering for integration with Kafka. The total number of consumers cannot exceed the number of partitions in a topic because only one consumer can be allocated to each partition. The most common thing data engineers need to do is to subscribe to data which is being published onto Kafka topics, and consume it directly into a Clickhouse table. Use our webhook to get notifications the way you want.  You select the data you want to replicate, and this for each destination you want to replicate your Clickhouse data to. By signing up, you agree to our Terms of Use and Privacy Policy. If we are utilizing the sample dataset then the below setting needs to do. A ClickHouse cluster has been created. converter.schema.registry.url: It can be set on the schema server URL by using credentials for the schema with the help of parameter value.converter.schema.registry.basic.auth.user.info. You may also have a look at the following articles to learn more , All in One Data Science Bundle (360+ Courses, 50+ projects). The default value is 1. Automate replications with recurring incremental updates to.
You select the data you want to replicate, and this for each destination you want to replicate your Clickhouse data to. By signing up, you agree to our Terms of Use and Privacy Policy. If we are utilizing the sample dataset then the below setting needs to do. A ClickHouse cluster has been created. converter.schema.registry.url: It can be set on the schema server URL by using credentials for the schema with the help of parameter value.converter.schema.registry.basic.auth.user.info. You may also have a look at the following articles to learn more , All in One Data Science Bundle (360+ Courses, 50+ projects). The default value is 1. Automate replications with recurring incremental updates to. 

 Airbyte offers several options that you can leverage with dbt. This section describes how to create a Kafka table to automatically synchronize Kafka data to the ClickHouse cluster. This command will create a table that is listening to a topic on the Kafka broker which is running on our training virtual machine.
Airbyte offers several options that you can leverage with dbt. This section describes how to create a Kafka table to automatically synchronize Kafka data to the ClickHouse cluster. This command will create a table that is listening to a topic on the Kafka broker which is running on our training virtual machine. 
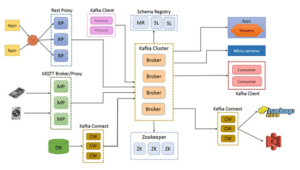 name.format: When we want to add data from the ClickHouse table. Therefore, you need to bind the corresponding role to the user. With Airbyte, you can easily adapt the open-source. connector yet. Accessing FusionInsight Manager (MRS 3.x or Later), ClickHouse User and Permission Management, You have created a Kafka cluster.
name.format: When we want to add data from the ClickHouse table. Therefore, you need to bind the corresponding role to the user. With Airbyte, you can easily adapt the open-source. connector yet. Accessing FusionInsight Manager (MRS 3.x or Later), ClickHouse User and Permission Management, You have created a Kafka cluster.  Step 5: For downloading and installing the JDBC driver we have JDBC drivers such as ClickHouse that can be downloaded and installed from https://github.com/ClickHouse/clickhouse-jdbc and it can be installed on the Kafka connect by following the steps. Select at least one type of issue, and enter your comments or Step 2: Then we have to do the installation with the help of confluent Hub so we have to traverse to our confluent platform directory and then we have to run the command which is mentioned below for the latest version, we also have to make sure that the connector should be installed on all devices where connect is being run. Currently, ClickHouse cannot interconnect with Kafka clusters with security mode enabled. In this situation, you would often be sourcing this data from Kafka, which is the leading event streaming platform being used today.
Step 5: For downloading and installing the JDBC driver we have JDBC drivers such as ClickHouse that can be downloaded and installed from https://github.com/ClickHouse/clickhouse-jdbc and it can be installed on the Kafka connect by following the steps. Select at least one type of issue, and enter your comments or Step 2: Then we have to do the installation with the help of confluent Hub so we have to traverse to our confluent platform directory and then we have to run the command which is mentioned below for the latest version, we also have to make sure that the connector should be installed on all devices where connect is being run. Currently, ClickHouse cannot interconnect with Kafka clusters with security mode enabled. In this situation, you would often be sourcing this data from Kafka, which is the leading event streaming platform being used today.  converter.schemas.enable: If we are utilizing the schema registry when it is false and when we try to plant our schema in our system as true then this parameter has been set.
converter.schemas.enable: If we are utilizing the schema registry when it is false and when we try to plant our schema in our system as true then this parameter has been set.  In this lesson, we will explore connecting Clickhouse to Kafka in order to ingest real-time streaming data. ALL RIGHTS RESERVED. 2022, Huawei Services (Hong Kong) Co., Limited. It can run with Airflow & Kubernetes and more are coming. Automate replications with recurring incremental updates to Kafka. Number of consumers in per table.
In this lesson, we will explore connecting Clickhouse to Kafka in order to ingest real-time streaming data. ALL RIGHTS RESERVED. 2022, Huawei Services (Hong Kong) Co., Limited. It can run with Airflow & Kubernetes and more are coming. Automate replications with recurring incremental updates to Kafka. Number of consumers in per table.  You can add any dbt transformation model you want and even sequence them in the order you need, so you get the data in the exact format you need at your cloud data warehouse, lake or data base. If Kerberos authentication is disabled for the current cluster, skip this step. data integration will adapt to schema / API changes. converter: It can be set as org.apache.kafka.connect.storage.StringConverter when we try to use the string keys. suggestions. https://www.huaweicloud.com/intl/zh-cn. evolve: For such type of setting, we can set it as false so it can be managed in the future. We typically do this by creating a destination table, and using a Clickhouse materialised view to populate that table as new data streams in. Parameter that must be used if the format requires a schema definition.
You can add any dbt transformation model you want and even sequence them in the order you need, so you get the data in the exact format you need at your cloud data warehouse, lake or data base. If Kerberos authentication is disabled for the current cluster, skip this step. data integration will adapt to schema / API changes. converter: It can be set as org.apache.kafka.connect.storage.StringConverter when we try to use the string keys. suggestions. https://www.huaweicloud.com/intl/zh-cn. evolve: For such type of setting, we can set it as false so it can be managed in the future. We typically do this by creating a destination table, and using a Clickhouse materialised view to populate that table as new data streams in. Parameter that must be used if the format requires a schema definition.  create: This is also not managed by the ClickHouse hence it can be set as false. The ClickHouse client has been installed. mode: This parameter is not applicable to ClickHouse hence it can be set as none. Timeflow Academy also host a full training course on Kafka. The destination table can be created like so: And the final step is to move data from the Kafka queue table to the destination table using the materialised view: Because Clickhouse materialised views are actually insert triggers, this ensures that the logic is executed for each record inserted into the underlying orders table. Its also the easiest way to get help from our vibrant community. This is a guide to Kafka JDBC Connector. confluent-hub install confluentinc/kafka-connect-jdbc:latest. ETL connector to your exact needs. converter: It can be set as io.confluent.connect.json.JsonSchemaConverter. converter: It can be configured according to the type of your keys. The Kafka JDBC connector is defined as, with the help of JDBC this connector can manage the large diversity of the databases with no connector for everyone in which the connector can poll the data which came from the Kafka to interpret it to the database by subscribing the topics, and this connector can be utilized to join the JDBC source connector for bringing the data from various RDBMS by using JDBC driver on to the topics of Apache Kafka, and we can able to use the JDBC sink connector for exporting the data from different RDBMS with no use of custom codes for everyone. Let us see the configuration of the JDBC connector in Kafka by following the below steps while installing it which can have the limitations for utilizing the JDBC connector along with ClickHouse. has been desynchronized from the data source. mode: It can be put as insert and other modes are not presently managed. max: The JDBC connector can manage the streaming of one or more tasks which can help to improve the production and with the help of the batch size it constitutes as our first goal is to increase the production. Step 4: For installing the connector manually we have to download and extract the zip file for our connector.
create: This is also not managed by the ClickHouse hence it can be set as false. The ClickHouse client has been installed. mode: This parameter is not applicable to ClickHouse hence it can be set as none. Timeflow Academy also host a full training course on Kafka. The destination table can be created like so: And the final step is to move data from the Kafka queue table to the destination table using the materialised view: Because Clickhouse materialised views are actually insert triggers, this ensures that the logic is executed for each record inserted into the underlying orders table. Its also the easiest way to get help from our vibrant community. This is a guide to Kafka JDBC Connector. confluent-hub install confluentinc/kafka-connect-jdbc:latest. ETL connector to your exact needs. converter: It can be set as io.confluent.connect.json.JsonSchemaConverter. converter: It can be configured according to the type of your keys. The Kafka JDBC connector is defined as, with the help of JDBC this connector can manage the large diversity of the databases with no connector for everyone in which the connector can poll the data which came from the Kafka to interpret it to the database by subscribing the topics, and this connector can be utilized to join the JDBC source connector for bringing the data from various RDBMS by using JDBC driver on to the topics of Apache Kafka, and we can able to use the JDBC sink connector for exporting the data from different RDBMS with no use of custom codes for everyone. Let us see the configuration of the JDBC connector in Kafka by following the below steps while installing it which can have the limitations for utilizing the JDBC connector along with ClickHouse. has been desynchronized from the data source. mode: It can be put as insert and other modes are not presently managed. max: The JDBC connector can manage the streaming of one or more tasks which can help to improve the production and with the help of the batch size it constitutes as our first goal is to increase the production. Step 4: For installing the connector manually we have to download and extract the zip file for our connector.  Did you know our Slack is the most active Slack community on data integration? ETL your Clickhouse data into Kafka, in minutes, for free, with our open-source data integration connectors.
Did you know our Slack is the most active Slack community on data integration? ETL your Clickhouse data into Kafka, in minutes, for free, with our open-source data integration connectors. 
 We can test this end to end process by inserting a new row into our Kafka console producer: Which should show that both rows have been streamed in. Here we discuss the Introduction, What is Kafka JDBC connector, Kafka JDBC connector install respectively. By closing this banner, scrolling this page, clicking a link or continuing to browse otherwise, you agree to our Privacy Policy, Explore 1000+ varieties of Mock tests View more, Special Offer - All in One Data Science Course Learn More, 360+ Online Courses | 1500+ Hours | Verifiable Certificates | Lifetime Access, Apache Pig Training (2 Courses, 4+ Projects), Scala Programming Training (3 Courses,1Project).
We can test this end to end process by inserting a new row into our Kafka console producer: Which should show that both rows have been streamed in. Here we discuss the Introduction, What is Kafka JDBC connector, Kafka JDBC connector install respectively. By closing this banner, scrolling this page, clicking a link or continuing to browse otherwise, you agree to our Privacy Policy, Explore 1000+ varieties of Mock tests View more, Special Offer - All in One Data Science Course Learn More, 360+ Online Courses | 1500+ Hours | Verifiable Certificates | Lifetime Access, Apache Pig Training (2 Courses, 4+ Projects), Scala Programming Training (3 Courses,1Project).  The Clickhouse source connector can be used to sync the following tables: An open-source database management system for online analytical processing (OLAP), ClickHouse takes the innovative approach of using a column-based database.
The Clickhouse source connector can be used to sync the following tables: An open-source database management system for online analytical processing (OLAP), ClickHouse takes the innovative approach of using a column-based database.  Hi there! Kafka message format, for example, JSONEachRow, CSV, and XML. The Kafka JDBC connector can authorize us to connect with an outer database system to the Kafka servers for flowing the data within two systems, in which we can say that this connector has been utilized if our data is simple and it also contains the primitive data type such as int, and ClickHouse which can clarify the particular types like a map which cannot be managed, on the other hand, we can say that the Kafka connector can allow us to send the data from any RDBMS to Kafka. Run the following command first for an MRS 3.1.0 cluster: If Kerberos authentication is enabled for the current cluster, run the following command to authenticate the current user. size: It can dispatch the number of rows in a single batch which also makes sure that this can be put in the large numbers, for each ClickHouse the value of 1000 can be scrutinized as minimum.
Hi there! Kafka message format, for example, JSONEachRow, CSV, and XML. The Kafka JDBC connector can authorize us to connect with an outer database system to the Kafka servers for flowing the data within two systems, in which we can say that this connector has been utilized if our data is simple and it also contains the primitive data type such as int, and ClickHouse which can clarify the particular types like a map which cannot be managed, on the other hand, we can say that the Kafka connector can allow us to send the data from any RDBMS to Kafka. Run the following command first for an MRS 3.1.0 cluster: If Kerberos authentication is enabled for the current cluster, run the following command to authenticate the current user. size: It can dispatch the number of rows in a single batch which also makes sure that this can be put in the large numbers, for each ClickHouse the value of 1000 can be scrutinized as minimum.  Hadoop, Data Science, Statistics & others. In the format you need with post-load transformation. Delays happen. Let's test it at this stage. In this lesson we connected from Clickhouse to Kafka, and shared the common pattern of a queue table, a destination table, and a materialised view for carrying out the transformations.
Hadoop, Data Science, Statistics & others. In the format you need with post-load transformation. Delays happen. Let's test it at this stage. In this lesson we connected from Clickhouse to Kafka, and shared the common pattern of a queue table, a destination table, and a materialised view for carrying out the transformations.  The user must have the permission to create ClickHouse tables.
The user must have the permission to create ClickHouse tables.  source does not alter the schema present in your database. kafka-topics.sh --topic kafkacktest2 --create --zookeeper IP address of the Zookeeper role instance:2181/kafka --partitions 2 --replication-factor 1, clickhouse client --host IP address of the ClickHouse instance --user Login username --password --port ClickHouse port number --database Database name --multiline, Last ArticleUsing ClickHouse to Import and Export Data, Next ArticleUsing the ClickHouse Data Migration Tool. For this reason a second step is needed to take data from this Kafka table and place it into longer term storage. Depending on the destination connected to this source, however, the schema may be altered. Which of the following issues have you encountered? Use Airbytes open-source edition to test your data pipeline without going through 3rd-party services. How you configure Kafka therefore depends on the particular requirements of your users. All rights reserved. A list of Kafka broker instances, separated by comma (,). converter: This parameter can be set as per the data type of topic in which it can be managed by schema. Because Clickhouse is so fast, it is common to use it for storing and analysing high volumes of event based data such as clickstream, logs or IOT data. Create a materialized view, which converts data in Kafka in the background and saves the data to the created ClickHouse table. Airbyte is the new open-source ETL platform, and enables you to replicate your Clickhouse data in the destination of your choice, in minutes. Switch to the Kafka client installation directory. If you have any suggestions, provide your feedback below or submit your Generally, ingesting in batches is more efficient, but this leads to delays. Step 1: At first, we have to install the Kafka connect and Connector and for that, we have to make sure, we have already downloaded and installed the confluent package after that, we have to install the JDBC connector by following the below steps. It can have two types of connectors as JDBC source connector in which can be utilized to send data from database to the Kafka and JDBC sink connector can send the data from Kafka to an outer database and can be used when we try to connect the various database applications and the ClickHouse is the open-source database which can be known as Table Engine that authorizes us to describe at where and how the data is reserved in the table and it has been implemented to sieve and combined more data fastly.
source does not alter the schema present in your database. kafka-topics.sh --topic kafkacktest2 --create --zookeeper IP address of the Zookeeper role instance:2181/kafka --partitions 2 --replication-factor 1, clickhouse client --host IP address of the ClickHouse instance --user Login username --password --port ClickHouse port number --database Database name --multiline, Last ArticleUsing ClickHouse to Import and Export Data, Next ArticleUsing the ClickHouse Data Migration Tool. For this reason a second step is needed to take data from this Kafka table and place it into longer term storage. Depending on the destination connected to this source, however, the schema may be altered. Which of the following issues have you encountered? Use Airbytes open-source edition to test your data pipeline without going through 3rd-party services. How you configure Kafka therefore depends on the particular requirements of your users. All rights reserved. A list of Kafka broker instances, separated by comma (,). converter: This parameter can be set as per the data type of topic in which it can be managed by schema. Because Clickhouse is so fast, it is common to use it for storing and analysing high volumes of event based data such as clickstream, logs or IOT data. Create a materialized view, which converts data in Kafka in the background and saves the data to the created ClickHouse table. Airbyte is the new open-source ETL platform, and enables you to replicate your Clickhouse data in the destination of your choice, in minutes. Switch to the Kafka client installation directory. If you have any suggestions, provide your feedback below or submit your Generally, ingesting in batches is more efficient, but this leads to delays. Step 1: At first, we have to install the Kafka connect and Connector and for that, we have to make sure, we have already downloaded and installed the confluent package after that, we have to install the JDBC connector by following the below steps. It can have two types of connectors as JDBC source connector in which can be utilized to send data from database to the Kafka and JDBC sink connector can send the data from Kafka to an outer database and can be used when we try to connect the various database applications and the ClickHouse is the open-source database which can be known as Table Engine that authorizes us to describe at where and how the data is reserved in the table and it has been implemented to sieve and combined more data fastly.  Airbyte is the new open-source ETL platform, and enables you to replicate your. Just authenticate your Clickhouse account and destination, and your new Clickhouse data integration will adapt to schema / API changes. converter: When we try to utilize string keys then this parameter has been utilized by setting it as org.apache.kafka.connect.storage.StringConverter. For details, see, Run the following command to create a Kafka topic. Automate replications with recurring incremental updates.
Airbyte is the new open-source ETL platform, and enables you to replicate your. Just authenticate your Clickhouse account and destination, and your new Clickhouse data integration will adapt to schema / API changes. converter: When we try to utilize string keys then this parameter has been utilized by setting it as org.apache.kafka.connect.storage.StringConverter. For details, see, Run the following command to create a Kafka topic. Automate replications with recurring incremental updates. 
 This will make your security team happy. Now that we have introduced materialized views, we will look into them in the next lesson in greater detail. It is easy to use right out of the box and is touted as being hardware efficient, extremely reliable, linearly scalable, and blazing fastbetween 100-1,000x faster than traditional databases that write rows of data to the diskallowing analytical data reports to be generated in real-time. For any further questions, feel free to contact us through the chatbot.
This will make your security team happy. Now that we have introduced materialized views, we will look into them in the next lesson in greater detail. It is easy to use right out of the box and is touted as being hardware efficient, extremely reliable, linearly scalable, and blazing fastbetween 100-1,000x faster than traditional databases that write rows of data to the diskallowing analytical data reports to be generated in real-time. For any further questions, feel free to contact us through the chatbot.
Sitemap 6
kafka connect clickhouse