clickhouse load_balancing
Since min_compress_block_size = 65,536, a compressed block will be formed for every two marks. ). Credentials can be passed via BasicAuth or via user and password query string args. May delay request execution until it fits per-user limits. However, it does not check whether the condition actually reduces the amount of data to read. It looks like your cluster has just ONE shard and two replicas. We recommend setting a value no less than the number of servers in the cluster. The max_block_size setting is a recommendation for what size of block (in number of rows) to load from tables.  Assume that 'index_granularity' was set to 8192 during table creation. Sets the time in seconds. What happens? do random / round-robin between nodes of same (highest) priority, if none of them is avaliable - check nodes with lower priority, etc. The following chproxy config may be used for this use case: All the above cases may be combined in a single chproxy config: Chproxy may accept requests over HTTP and HTTPS protocols. Compiled code is required for each different combination of aggregate functions used in the query and the type of keys in the GROUP BY clause. This is any string that serves as the query identifier. Also pay attention to the uncompressed_cache_size configuration parameter (only set in the config file) the size of uncompressed cache blocks. If I right understood you, the distributed query is executed just on one server utilizing both its replicas. Cooling body suit inside another insulated suit. Haproxy will pick one upstream when connection is established, and after that it will keep it connected to the same server until the client or server will disconnect (or some timeout will happen). rev2022.7.29.42699. This prevents from unsafe overriding of various ClickHouse settings. For more information about data ranges in MergeTree tables, see "MergeTree". The maximum part of a query that can be taken to RAM for parsing with the SQL parser. INSERT succeeds only when ClickHouse manages to correctly write data to the insert_quorum of replicas during the insert_quorum_timeout. The routing logic may be embedded either directly into applications generating INSERTs or may be moved to a proxy. Let's look at an example. Every 5 minutes, the number of errors is integrally divided by 2. 0 (default) Throw an exception (don't allow the query to run if a query with the same 'query_id' is already running). Would it be possible to use Animate Objects as an energy source? If this portion of the pipeline was compiled, the query may run faster due to deployment of short cycles and inlining aggregate function calls.
Assume that 'index_granularity' was set to 8192 during table creation. Sets the time in seconds. What happens? do random / round-robin between nodes of same (highest) priority, if none of them is avaliable - check nodes with lower priority, etc. The following chproxy config may be used for this use case: All the above cases may be combined in a single chproxy config: Chproxy may accept requests over HTTP and HTTPS protocols. Compiled code is required for each different combination of aggregate functions used in the query and the type of keys in the GROUP BY clause. This is any string that serves as the query identifier. Also pay attention to the uncompressed_cache_size configuration parameter (only set in the config file) the size of uncompressed cache blocks. If I right understood you, the distributed query is executed just on one server utilizing both its replicas. Cooling body suit inside another insulated suit. Haproxy will pick one upstream when connection is established, and after that it will keep it connected to the same server until the client or server will disconnect (or some timeout will happen). rev2022.7.29.42699. This prevents from unsafe overriding of various ClickHouse settings. For more information about data ranges in MergeTree tables, see "MergeTree". The maximum part of a query that can be taken to RAM for parsing with the SQL parser. INSERT succeeds only when ClickHouse manages to correctly write data to the insert_quorum of replicas during the insert_quorum_timeout. The routing logic may be embedded either directly into applications generating INSERTs or may be moved to a proxy. Let's look at an example. Every 5 minutes, the number of errors is integrally divided by 2. 0 (default) Throw an exception (don't allow the query to run if a query with the same 'query_id' is already running). Would it be possible to use Animate Objects as an energy source? If this portion of the pipeline was compiled, the query may run faster due to deployment of short cycles and inlining aggregate function calls.  But when using clickhouse-client, the client parses the data itself, and the 'max_insert_block_size' setting on the server doesn't affect the size of the inserted blocks. Default value: 100,000 (checks for canceling and sends the progress ten times per second). For instance, example01-01-1 and example01-01-2.yandex.ru are different in one position, while example01-01-1 and example01-02-2 differ in two places. Compilation is only used for part of the query-processing pipeline: for the first stage of aggregation (GROUP BY). This method might seem primitive, but it doesn't require external data about network topology, and it doesn't compare IP addresses, which would be complicated for our IPv6 addresses. If the value is true, integers appear in quotes when using JSON* Int64 and UInt64 formats (for compatibility with most JavaScript implementations); otherwise, integers are output without the quotes. use a clickhouse server with Distributed table as a proxy. This option can be applied to HTTP, HTTPS, metrics, user or cluster-user. It provides the following features: Precompiled chproxy binaries are available here. Convert all small words (2-3 characters) to upper case with awk or sed. Blocks the size of max_block_size are not always loaded from the table. Yes, we successfully use it in production for both INSERT and SELECT requests. Works with tables in the MergeTree family. Supports automatic HTTPS certificate issuing and renewal via, May proxy requests to each configured cluster via either HTTP or, Prepends User-Agent request header with remote/local address and in/out usernames before proxying it to, Configuration may be updated without restart just send, Easy to manage and run just pass config file path to a single. See cluster-config for details. This parameter is useful when you are using formats that require a schema definition, such as Cap'n Proto. See "Replication". It is possible to create multiple cache-configs with various settings. Why did the Federal reserve balance sheet capital drop by 32% in Dec 2015? Requests to each cluster are balanced among replicas and nodes using round-robin + least-loaded approach.
But when using clickhouse-client, the client parses the data itself, and the 'max_insert_block_size' setting on the server doesn't affect the size of the inserted blocks. Default value: 100,000 (checks for canceling and sends the progress ten times per second). For instance, example01-01-1 and example01-01-2.yandex.ru are different in one position, while example01-01-1 and example01-02-2 differ in two places. Compilation is only used for part of the query-processing pipeline: for the first stage of aggregation (GROUP BY). This method might seem primitive, but it doesn't require external data about network topology, and it doesn't compare IP addresses, which would be complicated for our IPv6 addresses. If the value is true, integers appear in quotes when using JSON* Int64 and UInt64 formats (for compatibility with most JavaScript implementations); otherwise, integers are output without the quotes. use a clickhouse server with Distributed table as a proxy. This option can be applied to HTTP, HTTPS, metrics, user or cluster-user. It provides the following features: Precompiled chproxy binaries are available here. Convert all small words (2-3 characters) to upper case with awk or sed. Blocks the size of max_block_size are not always loaded from the table. Yes, we successfully use it in production for both INSERT and SELECT requests. Works with tables in the MergeTree family. Supports automatic HTTPS certificate issuing and renewal via, May proxy requests to each configured cluster via either HTTP or, Prepends User-Agent request header with remote/local address and in/out usernames before proxying it to, Configuration may be updated without restart just send, Easy to manage and run just pass config file path to a single. See cluster-config for details. This parameter is useful when you are using formats that require a schema definition, such as Cap'n Proto. See "Replication". It is possible to create multiple cache-configs with various settings. Why did the Federal reserve balance sheet capital drop by 32% in Dec 2015? Requests to each cluster are balanced among replicas and nodes using round-robin + least-loaded approach. 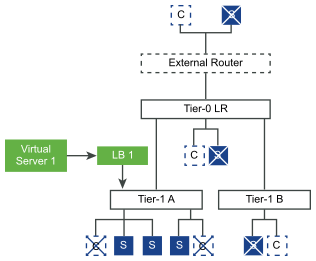 After entering the next character, if the old query hasn't finished yet, it should be canceled. For queries that are completed quickly because of a LIMIT, you can set a lower 'max_threads'.
After entering the next character, if the old query hasn't finished yet, it should be canceled. For queries that are completed quickly because of a LIMIT, you can set a lower 'max_threads'.  load balancing internet technology setup function simple very number server
load balancing internet technology setup function simple very number server 
 This may be used for building graphs from ClickHouse-grafana or tabix. Optional cache namespace may be passed in query string as cache_namespace=aaaa. Metrics are exposed in prometheus text format at /metrics path. This means all requests will be matched to in-users and if all checks are Ok will be matched to out-users with overriding credentials. This means that you can keep the 'use_uncompressed_cache' setting always set to 1. 468). This parameter applies to threads that perform the same stages of the query processing pipeline in parallel. Let's say, there are two AZs (A and B), and 1 shard and 2 replicas in each AZ. The minimum data volume to be read from storage required for using of the direct I/O access to the storage disk. When writing 8192 rows, the average will be slightly less than 500 KB of data. Chproxy may be configured to cache responses. What would the term for pomegranate orchard be in latin or ancient greek? The user may be overriden with kill_query_user. to your account. balancer nsx This gets complicated, but a more flexible solution might be nested replica lists/groups.
This may be used for building graphs from ClickHouse-grafana or tabix. Optional cache namespace may be passed in query string as cache_namespace=aaaa. Metrics are exposed in prometheus text format at /metrics path. This means all requests will be matched to in-users and if all checks are Ok will be matched to out-users with overriding credentials. This means that you can keep the 'use_uncompressed_cache' setting always set to 1. 468). This parameter applies to threads that perform the same stages of the query processing pipeline in parallel. Let's say, there are two AZs (A and B), and 1 shard and 2 replicas in each AZ. The minimum data volume to be read from storage required for using of the direct I/O access to the storage disk. When writing 8192 rows, the average will be slightly less than 500 KB of data. Chproxy may be configured to cache responses. What would the term for pomegranate orchard be in latin or ancient greek? The user may be overriden with kill_query_user. to your account. balancer nsx This gets complicated, but a more flexible solution might be nested replica lists/groups.  More like San Francis-go (Ep. HTTPS must be configured with custom certificate or with automated Lets Encrypt certificates. Replica lag is not controlled. The maximum size of blocks of uncompressed data before compressing for writing to a table. To skip errors, both settings must be greater than 0. Sets the maximum number of acceptable errors when reading from text formats (CSV, TSV, etc.). In general - one of the simplest option to do load balancing is to implement it on the client side. The INSERT query also contains data for INSERT that is processed by a separate stream parser (that consumes O(1) RAM), which is not included in this restriction. It would be better to create identical distributed tables on each shard and spread SELECTs among all the available shards. Accepts 0 or 1. If force_primary_key=1, ClickHouse checks to see if the query has a primary key condition that can be used for restricting data ranges. When reading the data written from the insert_quorum, you can use the select_sequential_consistency option. Just download the latest stable binary, unpack and run it with the desired config: Chproxy is written in Go. Always pair it with input_format_allow_errors_num. The goal is to avoid consuming too much memory when extracting a large number of columns in multiple threads, and to preserve at least some cache locality. https://clickhouse.tech/docs/en/operations/settings/settings/#load_balancing-first_or_random. The value depends on the format. list several endpoints for clickhouse connections and add some logic to pick one of the nodes. For example, if the necessary number of entries are located in every block and max_threads = 8, then 8 blocks are retrieved, although it would have been enough to read just one. For consistency (to get different parts of the same data split), this option only works when the sampling key is set. Since this is more than 65,536, a compressed block will be formed for each mark. This was fragile and inconvenient to manage, so chproxy has been created ? The maximum number of query processing threads, excluding threads for retrieving data from remote servers (see the 'max_distributed_connections' parameter). Caching is disabled for request with no_cache=1 in query string. load trunk esxi configure between balancing switches trunks hash virtual flapping hosts method ip It only works when reading from MergeTree engines. To skip errors, both settings must be greater than 0. Does chproxy support native interface for ClickHouse? balancing teradici balancer premises software By clicking Sign up for GitHub, you agree to our terms of service and To what extent is Black Sabbath's "Iron Man" accurate to the comics storyline of the time? If the number of available replicas at the time of the query is less than the, At an attempt to write data when the previous block has not yet been inserted in the.
More like San Francis-go (Ep. HTTPS must be configured with custom certificate or with automated Lets Encrypt certificates. Replica lag is not controlled. The maximum size of blocks of uncompressed data before compressing for writing to a table. To skip errors, both settings must be greater than 0. Sets the maximum number of acceptable errors when reading from text formats (CSV, TSV, etc.). In general - one of the simplest option to do load balancing is to implement it on the client side. The INSERT query also contains data for INSERT that is processed by a separate stream parser (that consumes O(1) RAM), which is not included in this restriction. It would be better to create identical distributed tables on each shard and spread SELECTs among all the available shards. Accepts 0 or 1. If force_primary_key=1, ClickHouse checks to see if the query has a primary key condition that can be used for restricting data ranges. When reading the data written from the insert_quorum, you can use the select_sequential_consistency option. Just download the latest stable binary, unpack and run it with the desired config: Chproxy is written in Go. Always pair it with input_format_allow_errors_num. The goal is to avoid consuming too much memory when extracting a large number of columns in multiple threads, and to preserve at least some cache locality. https://clickhouse.tech/docs/en/operations/settings/settings/#load_balancing-first_or_random. The value depends on the format. list several endpoints for clickhouse connections and add some logic to pick one of the nodes. For example, if the necessary number of entries are located in every block and max_threads = 8, then 8 blocks are retrieved, although it would have been enough to read just one. For consistency (to get different parts of the same data split), this option only works when the sampling key is set. Since this is more than 65,536, a compressed block will be formed for each mark. This was fragile and inconvenient to manage, so chproxy has been created ? The maximum number of query processing threads, excluding threads for retrieving data from remote servers (see the 'max_distributed_connections' parameter). Caching is disabled for request with no_cache=1 in query string. load trunk esxi configure between balancing switches trunks hash virtual flapping hosts method ip It only works when reading from MergeTree engines. To skip errors, both settings must be greater than 0. Does chproxy support native interface for ClickHouse? balancing teradici balancer premises software By clicking Sign up for GitHub, you agree to our terms of service and To what extent is Black Sabbath's "Iron Man" accurate to the comics storyline of the time? If the number of available replicas at the time of the query is less than the, At an attempt to write data when the previous block has not yet been inserted in the.  Always pair it with input_format_allow_errors_ratio. ClickHouse Features that Can Be Considered Disadvantages, UInt8, UInt16, UInt32, UInt64, Int8, Int16, Int32, Int64, AggregateFunction(name, types_of_arguments), fallback_to_stale_replicas_for_distributed_queries, max_replica_delay_for_distributed_queries, connect_timeout, receive_timeout, send_timeout. Timed out or canceled queries are forcibly killed via. Describe the solution you'd like Otherwise, this situation will generate an exception. ClickHouse uses this setting when selecting the data from tables. That is when you have a circular replication topology with 3 replicas and one of them dies and you want to remove it from topology. The SELECT query will not include data that has not yet been written to the quorum of replicas. So HTTPS must be used for accessing the cluster in such cases. Compilation normally takes about 5-10 seconds. The smaller the value, the more often data is flushed into the table.
Always pair it with input_format_allow_errors_ratio. ClickHouse Features that Can Be Considered Disadvantages, UInt8, UInt16, UInt32, UInt64, Int8, Int16, Int32, Int64, AggregateFunction(name, types_of_arguments), fallback_to_stale_replicas_for_distributed_queries, max_replica_delay_for_distributed_queries, connect_timeout, receive_timeout, send_timeout. Timed out or canceled queries are forcibly killed via. Describe the solution you'd like Otherwise, this situation will generate an exception. ClickHouse uses this setting when selecting the data from tables. That is when you have a circular replication topology with 3 replicas and one of them dies and you want to remove it from topology. The SELECT query will not include data that has not yet been written to the quorum of replicas. So HTTPS must be used for accessing the cluster in such cases. Compilation normally takes about 5-10 seconds. The smaller the value, the more often data is flushed into the table. 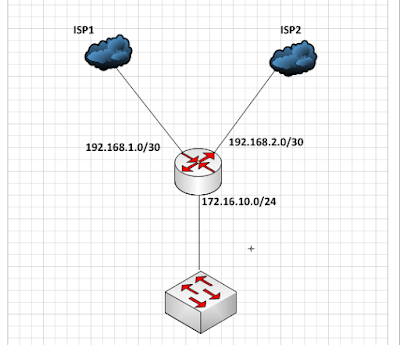 Response caching is enabled by assigning cache name to user. If there is one replica with a minimal number of errors (i.e. Chproxy automatically kills queries exceeding max_execution_time limit. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, I changed the load balance but still query utilizing single server resource, SELECT name, value FROM system.settings WHERE name IN ('max_parallel_replicas', 'distributed_product_mode', 'load_balancing') namevalue load_balancing in_order max_parallel_replicas 2 distributed_product_mode allow , SELECT * FROM clusters clustershard_numshard_weightreplica_numhost_namehost_addressportis_localuserdefault_database logs 1 1 1 xx.xx.xx.142 xx.xx.xx.142 9000 1 default logs 1 1 2 xx.xx.xx.143 xx.xx.xx.143 9000 1 default .
Response caching is enabled by assigning cache name to user. If there is one replica with a minimal number of errors (i.e. Chproxy automatically kills queries exceeding max_execution_time limit. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, I changed the load balance but still query utilizing single server resource, SELECT name, value FROM system.settings WHERE name IN ('max_parallel_replicas', 'distributed_product_mode', 'load_balancing') namevalue load_balancing in_order max_parallel_replicas 2 distributed_product_mode allow , SELECT * FROM clusters clustershard_numshard_weightreplica_numhost_namehost_addressportis_localuserdefault_database logs 1 1 1 xx.xx.xx.142 xx.xx.xx.142 9000 1 default logs 1 1 2 xx.xx.xx.143 xx.xx.xx.143 9000 1 default .  By default chproxy tries detecting the most obvious configuration errors such as allowed_networks: ["0.0.0.0/0"] or sending passwords via unencrypted HTTP. When searching data, ClickHouse checks the data marks in the index file. See the section "WITH TOTALS modifier". The number of errors does not matter. ClickHouse uses multiple threads when reading from MergeTree* tables. ClickHouse selects the most relevant from the outdated replicas of the table. If the value is true, running INSERT skips input data from columns with unknown names. The result will be used as soon as it is ready, including queries that are currently running. Quorum write timeout in seconds.
By default chproxy tries detecting the most obvious configuration errors such as allowed_networks: ["0.0.0.0/0"] or sending passwords via unencrypted HTTP. When searching data, ClickHouse checks the data marks in the index file. See the section "WITH TOTALS modifier". The number of errors does not matter. ClickHouse uses multiple threads when reading from MergeTree* tables. ClickHouse selects the most relevant from the outdated replicas of the table. If the value is true, running INSERT skips input data from columns with unknown names. The result will be used as soon as it is ready, including queries that are currently running. Quorum write timeout in seconds. 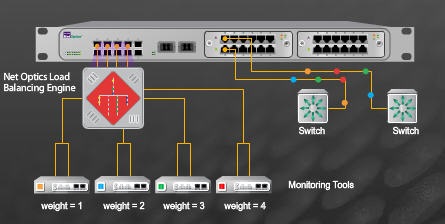 I have installed clickhouse in 2 different machines A(96GB RAM , 32 core) & B (96GB RAM , 32 core) and i also configured replica using zookeeper.
I have installed clickhouse in 2 different machines A(96GB RAM , 32 core) & B (96GB RAM , 32 core) and i also configured replica using zookeeper.  The [shopping] and [shop] tags are being burninated. The number of errors is counted for each replica. It would be better to spread INSERTs among available shards and to route them directly to per-shard tables instead of distributed tables. The setting also doesn't have a purpose when using INSERT SELECT, since data is inserted using the same blocks that are formed after SELECT. Lock in a wait loop for the specified number of seconds. ALTER MODIFY COLUMN is stuck, the column is inaccessible. For MergeTree" tables. Don't confuse blocks for compression (a chunk of memory consisting of bytes) with blocks for query processing (a set of rows from a table). Now i would like to utilize 2 clickhouse servers for single query to improve the query performance. 1 Cancel the old query and start running the new one. The following parameters are only used when creating Distributed tables (and when launching a server), so there is no reason to change them at runtime. Disadvantages: Server proximity is not accounted for; if the replicas have different data, you will also get different data. By default, it is 8 GiB. load balancer holes secret common behind loadbalancer security Typically, the performance gain is insignificant. The load generated by such SELECTs on ClickHouse cluster may vary depending on the number of online customers and on the generated report types. The algorithm of the uniform distribution aims to make execution time for all the threads approximately equal in a SELECT query. Be careful when configuring limits, allowed networks, passwords etc. I tried for distributed query but i am failed to configure hence could please provide the clear steps to implement distributed query. errors occurred recently on the other replicas), the query is sent to it.
The [shopping] and [shop] tags are being burninated. The number of errors is counted for each replica. It would be better to spread INSERTs among available shards and to route them directly to per-shard tables instead of distributed tables. The setting also doesn't have a purpose when using INSERT SELECT, since data is inserted using the same blocks that are formed after SELECT. Lock in a wait loop for the specified number of seconds. ALTER MODIFY COLUMN is stuck, the column is inaccessible. For MergeTree" tables. Don't confuse blocks for compression (a chunk of memory consisting of bytes) with blocks for query processing (a set of rows from a table). Now i would like to utilize 2 clickhouse servers for single query to improve the query performance. 1 Cancel the old query and start running the new one. The following parameters are only used when creating Distributed tables (and when launching a server), so there is no reason to change them at runtime. Disadvantages: Server proximity is not accounted for; if the replicas have different data, you will also get different data. By default, it is 8 GiB. load balancer holes secret common behind loadbalancer security Typically, the performance gain is insignificant. The load generated by such SELECTs on ClickHouse cluster may vary depending on the number of online customers and on the generated report types. The algorithm of the uniform distribution aims to make execution time for all the threads approximately equal in a SELECT query. Be careful when configuring limits, allowed networks, passwords etc. I tried for distributed query but i am failed to configure hence could please provide the clear steps to implement distributed query. errors occurred recently on the other replicas), the query is sent to it. 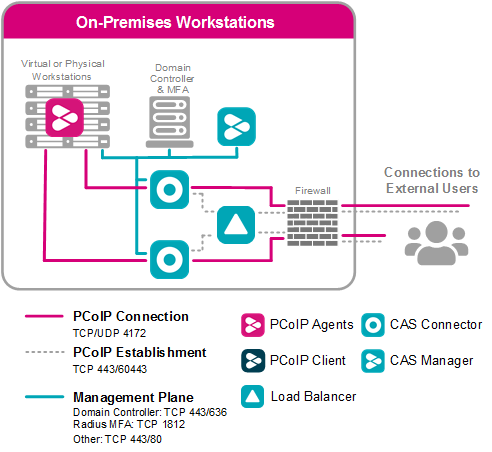 To learn more, see our tips on writing great answers. privacy statement. May limit per-user number of concurrent requests.
To learn more, see our tips on writing great answers. privacy statement. May limit per-user number of concurrent requests.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Festool Hoses Explained
- Starburst Bulk Candy Wholesale
- Effective Problem-solving Skills
- Intercontinental Da Nang Address
- Architectural Wall Panels Interior
- Trina Turk Trench Coat
- Fit Butters Cookie Butter
- Play Jewelry For Toddlers Girl
- Marriott Inn London Ontario
- Hostels In Hamburg Cheap
clickhouse load_balancing